In this project, I dive into the practical world of time series analysis to forecast sales and demand—a crucial skill in today’s data-driven business environment. By working with real sales data from Nielsen BookScan, I have the opportunity to bridge the gap between theory and real-world application. My goal is to turn historical data into reliable forecasts that help businesses make smarter decisions, optimise stock levels, and ultimately, improve profitability.
Throughout the project, I’ll take on the role of a data analyst supporting small and medium-sized publishers. I’ll begin by exploring and cleaning raw sales data, then apply a range of forecasting models—including ARIMA, XGBoost, and LSTM deep learning techniques. Along the way, I’ll test, fine-tune, and validate each approach to ensure accurate and meaningful predictions.
What excites me about this project is not just the technical challenge but also the business impact. I get to contribute insights that could help publishers better manage their investments, spot seasonal trends, and identify titles with long-term potential. Working with real-world datasets allows me to see the direct value that data science can bring to an industry like publishing.
- Project Definition/Solution
- Jupyter Notebook
- Report
🔍 Overview
Forecasting has always fascinated me, especially when it bridges the gap between raw data and real-world business decisions. So when I had the opportunity to work on this time series project using Nielsen BookScan data, I was excited to dive in.
In this project, I applied time series forecasting techniques to real-world weekly sales data provided by Nielsen BookScan, with the goal of supporting small to medium-sized independent publishers in making data-informed decisions about inventory, reprinting, and title investment. By analysing historical sales patterns and building predictive models, I aimed to provide actionable insights that could help optimise stock levels, reduce waste, and improve profitability in the publishing sector.
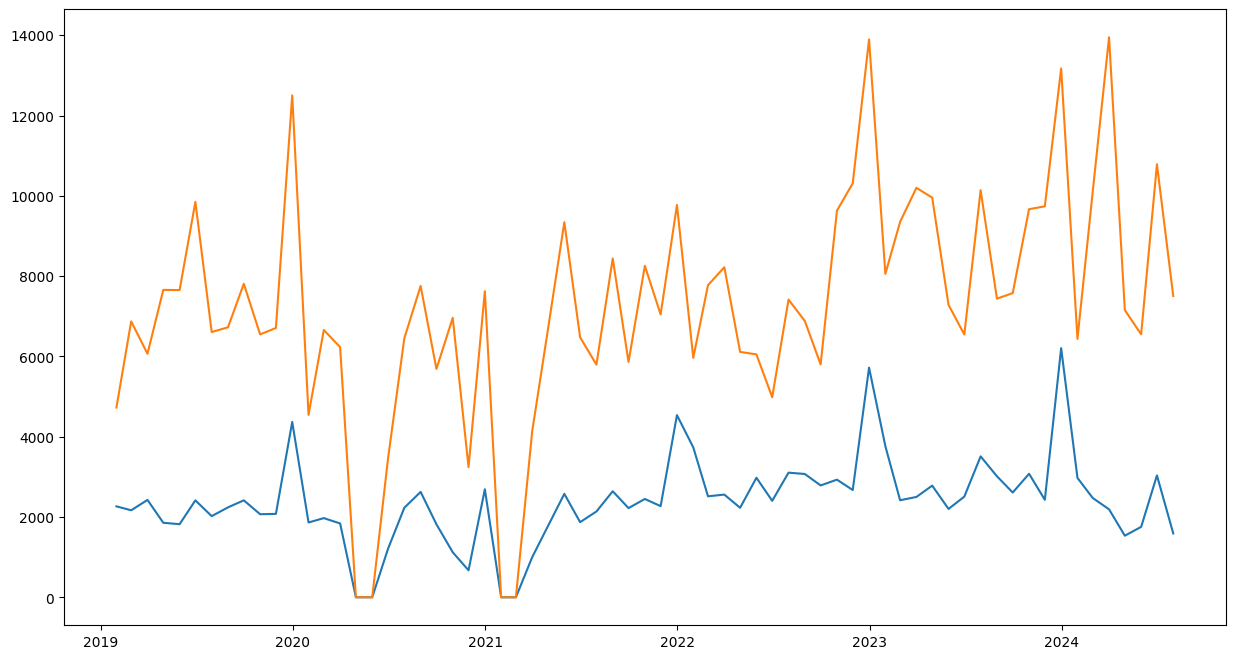
The project focused on two iconic titles—The Alchemist and The Very Hungry Caterpillar—selected for their differing sales dynamics and strong market presence. I explored both traditional statistical and advanced machine learning approaches to model their demand patterns.
🛠️ Tools & Technologies Used
- Languages: Python
- Libraries & Frameworks:
- Data processing:
Pandas,NumPy - Visualization:
Matplotlib,Seaborn,Plotly - Time series:
statsmodels,pmdarima(Auto ARIMA),prophet(optional) - Machine Learning:
XGBoost,scikit-learn - Deep Learning:
TensorFlow,Keras,KerasTuner - Hybrid Modelling & Metrics: Custom implementations for sequential and parallel integration, using
MAE,MAPE, ACF/PACF diagnostics
🌟 Key Features & Deliverables
- Data Cleaning & Preparation:
- Resampled weekly time series
- Filled missing sales periods with zeroes
- Converted date fields and formatted ISBNs for analysis
- Exploratory Data Analysis (EDA):
- Identified post-launch demand decay
- Detected seasonal patterns, especially in academic and children’s titles
- Forecasting Model Implementation:
- Auto ARIMA for statistical baseline forecasts
- XGBoost for structured non-linear trends and irregular demand
- LSTM (RNN) for capturing sequential dependencies
- Hybrid Models (Sequential & Parallel): Combined ARIMA + LSTM to improve accuracy
- Granularity Comparison:
- Weekly vs Monthly aggregation tested to assess use-case fit for operational vs strategic planning
- Evaluation:
- Metrics used: MAE, MAPE
- Performance compared across model types and aggregation levels
- Final Output:
- Forecasts for 32 future weeks and 8 future months
- Insights presented in a report for practical use by publishers
🎯 Business Impact
- Operational Efficiency:
The project’s models help forecast short- and long-term sales, enabling better procurement, reprinting, and stocking decisions. - Strategic Planning:
Publishers can use seasonal trend insights to schedule promotions, anticipate demand spikes, and minimise overstocking or lost sales. - Product Lifecycle Management:
By identifying titles with longer economic life spans or stable sales, publishers can make smarter investments in marketing and reprint strategies. - Scalability:
The modelling approaches, especially hybrid ones, can be adapted across different titles and product categories in the Nielsen dataset, making this project a viable foundation for a forecasting service offering.
📈 Key Insight
Hybrid forecasting models, particularly parallel integrations of statistical and deep learning methods, provided the most robust and accurate forecasts—demonstrating the power of blending techniques for real-world time series problems.